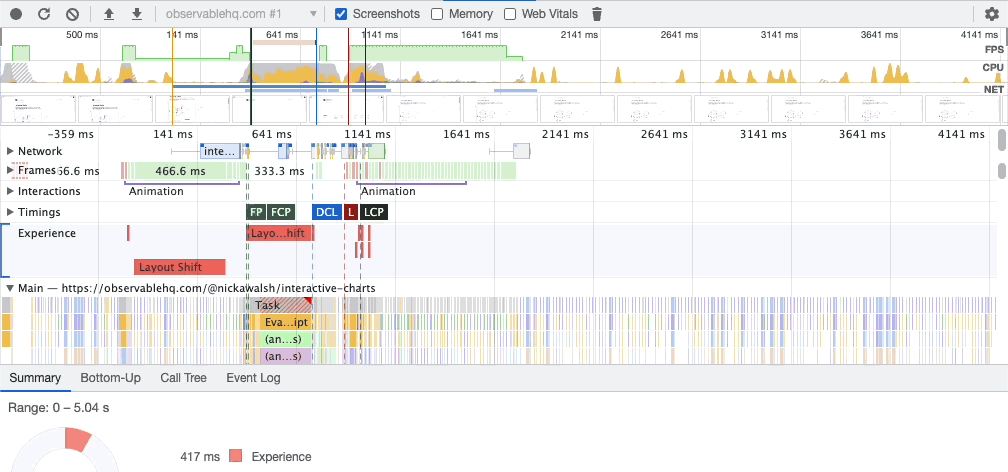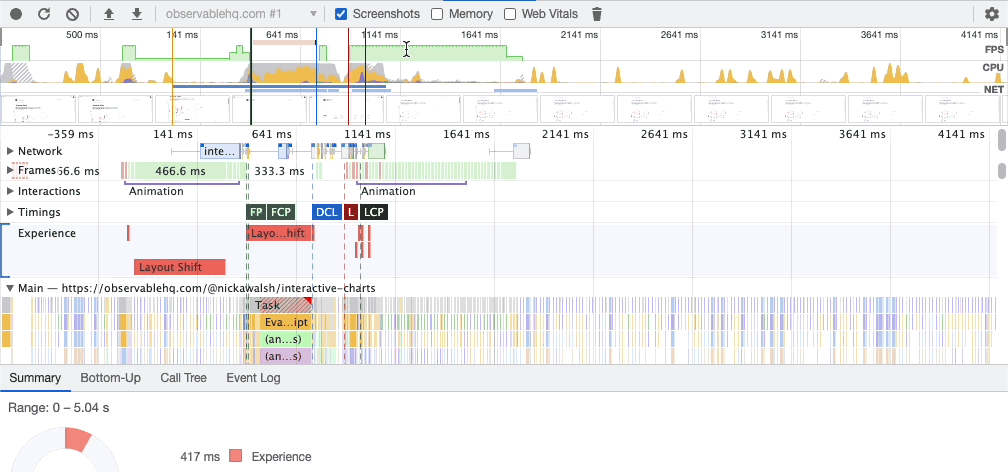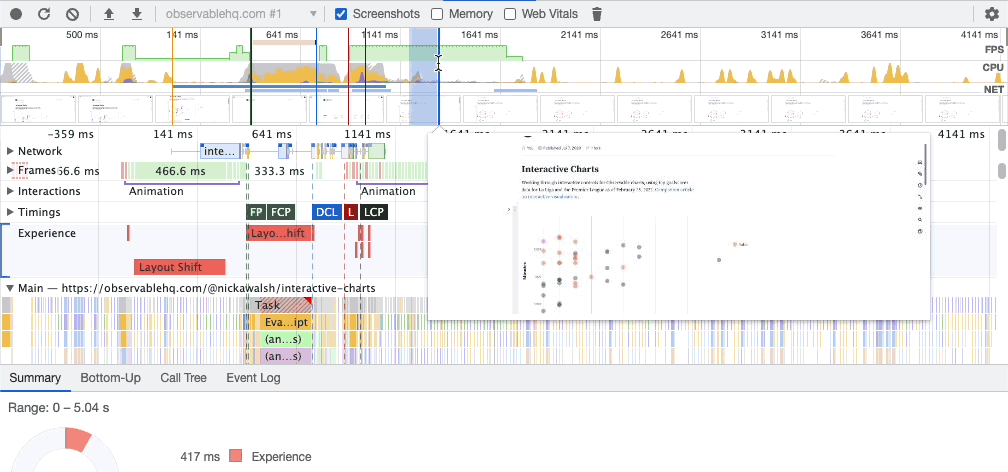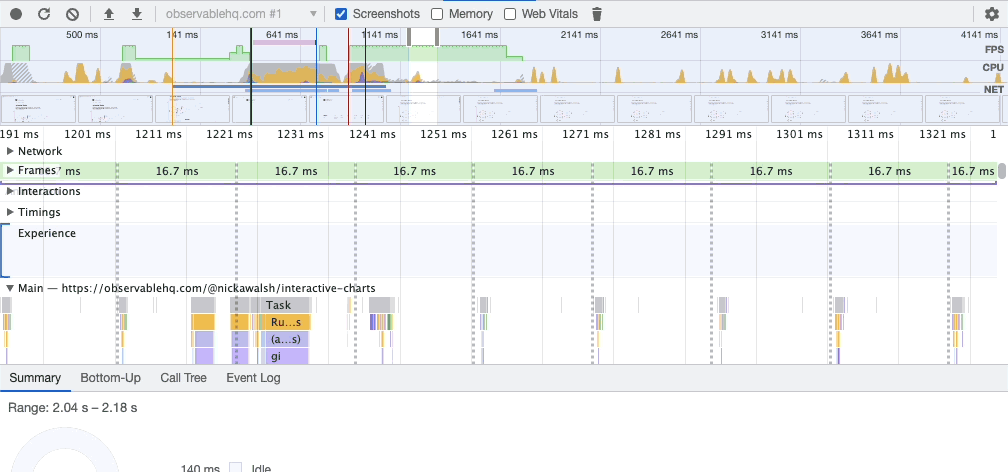
If you say “let’s add a search feature” to a team of five developers, they’ll each have something (wildly) different in their heads. Are results categorized? How are they ranked? Are there ads? What about autocomplete? Should the autocomplete use browser defaults or something custom? Do results get customized for the user’s recent searches or behaviors?
Documentation and requirements help paper over those questions, but there’s a root issue: They use a written medium to describe something complex, interactive, and primarily visual.
Communication is the big problem in software, popping up often in topics we’ve covered. Success is a moving target. Project teams are all unique, leaning on a combination of people, processes, and tools to tackle the problem — but there’s no perfect way forward.
Faced with those issues, what tools are worth using to marry visuals and communication? This article’s title is a bit of a spoiler, but build after build has solidified the humble wireframe as an absolute value engine.
When the budget or schedule is tight, though, many see wireframes as a deliverable worth skipping. They’re never seen by end users, and they put a roadblock in front of design and development getting going. Valid concerns, but short-sighted; as we’ll cover, those intermediary steps are really important for the overall project process.
Let’s take a look at the what and how in a bit more detail.
What is a Wireframe?
In the world of web development, wireframes are a tried-and-true old hat. For those not steeped in our industry, though, the concept is a relative unknown. Stepping back, it’s easy to see why: The name isn’t obvious, their use isn’t consistent, and even we aren’t quite sure of the origin story.
So, what’s a wireframe? It’s a low fidelity mockup; an approximation of an application with simplified details. Something like a quick sketch of a photograph.
It’s tough to know exactly when they became a “thing” for the web. The best approximation points at the early-to-mid 90s and confirms that the name wireframe is borrowed from 3D animation. In the 3D world, wireframes refer to a mesh-like representation of a model — viewing it without textures, shaders, and the like. These are fast to create, faster to edit, and because they lack fine detail, they’re often several orders of magnitude quicker than the final, high-fidelity rendering.

The Confusing Semantics Around Interface Wireframes
Just like the difference in how five developers would picture a search feature, each person’s idea of a wireframe is a little unique, too. There’s a pretty broad acceptance of just about anything that claims to be a “wireframe.”
That can include purely hand-drawn elements or digital precision:

Grayscale or the use of color:

Abstracted details or a thorough look:
And a number of other characteristics on a sliding scale. Interactive or static, fixed or responsive, key features or full compositions, and so forth.
Just to complicate things more, a wireframe can be whatever a project needs it to be. As we’ll cover from here on out, that extra bit of ambiguity has both positive and negative implications.
The Good Stuff About Wireframes
With history and semantics behind us, here’s a look at some key benefits to support our best communication tool claim.
Fast and Iterative Results
Compared to everything else you could be doing — be it detailed technical writing, full-fledged design, or development — wireframes are faster.
They thrive at the start of a project, where decisions and directions are fluid. If something big can change, your budget will really appreciate the tool that can absorb and reflect a new idea quickly.
Adjustable Fidelity and Cost
As we pointed out in the what section, the level of detail and effort that goes into a wireframe is on a sliding scale. Cost and speed, by extension, are also adjustable.
Have a concept with a ton of complexity that needs a stamp of approval from subject matter experts, legal, and management? Add plenty of detail. Did someone dream up a new feature in the shower that they want to quickly test? Draft up a quick, low-detail wireframe on a napkin.
Project Requirements, Visualized
Like seeing a globe instead of having it described to you, wireframes are the first bridge to a visual product. Requirements become tangible, real features. You’re left with the big picture, and it’s a very different angle than a collection of written ideas and needs.
Spatial (and Responsive) Thinking
Continuing on with the visual theme, wireframes also excel at pulling spatial considerations into the mix. Now we’re confronted by questions like:
- All things considered, what comes first?
- With limited room, does this feature make the cut?
- What action are we primarily incentivizing the user to do?
- How does this adapt to different screen sizes?
It’s the same concept as a common project discovery tool: The UX Sketching exercise. Participants use a fixed representation of a device screen (so, a box) and are tasked with sketching a specific view, like a dashboard or key page. The addition of layout surfaces important concerns around prioritization, usability, device needs, and information density, among others. In practice, the exercise is a limited, timed example of a wireframe.
A Progressive Stepping Stone
Software is hard to get right, and so is the communication that surrounds it. Anything we can do to make the process predictable is a win.
Hopping from requirements to a completed application (or even a fleshed out design) leaves too much room for surprise, misunderstandings, and the potential to miss the mark. Wireframes sit in the middle of that jump, adding a more comfortable step to expose miscommunications or unknowns along a path to remove risk.
Different Specializations, Same Page
Once we’ve combined the other key benefits, wireframes are the ultimate gut check. Domain experts across the team have a chance to weigh in on whether or not there’s something there worth building — and it’s hard to overstate how much value lives in that checkmark (or lack thereof).
The (Potential) Problems With Wireframes
Nothing comes without costs. The implications and freeform nature of wireframes bring a few potential issues along. As a cautionary exercise, we’ll detail some of the big ones.
Adjustable Fidelity and Cost
Yep, our first negative was also on the list of positives.
There’s a key problem with an ambiguous amount of effort, detail, and cost: Someone has to decide how much, and they won’t always be right. Fortunately, the price for getting it wrong is a good deal less than at later project stages.
If the wireframes go too abstract, you’re effectively kicking the can down the road and forcing the implementation team to handle the details — knocking out many of the key reasons they’re worth creating in the first place.
Filling in the Stylistic Gaps
Wireframes aren’t for everyone. Some folks aren’t practiced or attuned to the concept of looking at grayscale, abstract mockups and imagining what’s missing. It’s like walking through a framed house and trying to picture the materials, finishes, decorations, and furniture.

When this is an issue, creating wireframes for internal use (and critique) is still a worthy use of time.
Finding the Right Owner
As a tool, wireframes seem safe to assign to anyone. Customers won’t see them, they’re quick to change, and they’ll just kick off a number of discussions anyway.
In practice, they’re a specialization unto themselves. It’s a deliverable that marries several skills — covering the basics of design, development, and the subject matter expertise represented to showcase something that’s achievable and in budget. We’ve had the most luck leaning on designers with technical know-how or experienced front-end developers.
A Full Team Commitment
Getting to the sign-off point takes a reasonable portion (10–15% or more) of the project budget, since wireframes spark discussions, changes, estimates, approvals, and meetings. The good news? All of that work saves a boatload of time and money versus getting it wrong later.
Source of Truth or Drawings in the Sand?
When they’re done, should they be updated?
Wrapping up wireframes is a big step, but you’ll have to decide if they’ll be your source of truth from that point forward. If new project decisions are made and ideas diverge, the team needs to be on the same page when it comes to referring back to them.
A Love Letter to Our Favorite Communication Tool
The tried-and-true wireframe: A tool that can’t be overrated. They combine flexibility, speed, and an affinity for change that’s hard to match. They convey priorities, features, and complexities in a way that is both unambiguous and concise.
More than anything, they usually represent the first steps into visually representing an idea. It’s a logical and necessary stepping stone to bring a project team up to speed before diving into costly implementation efforts.


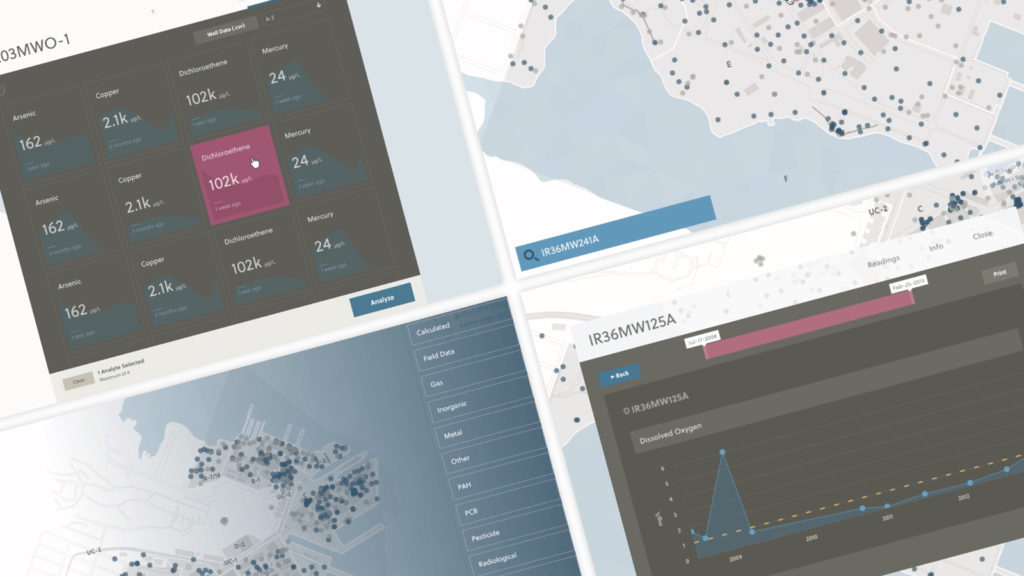

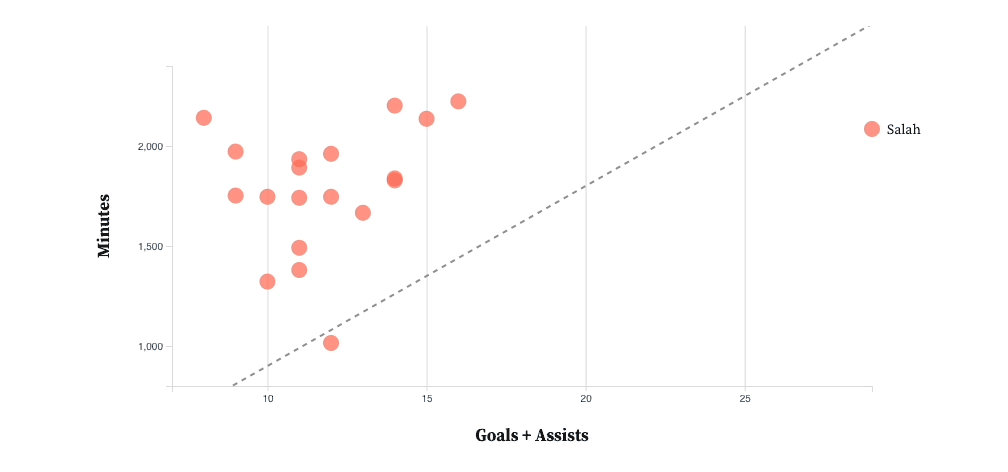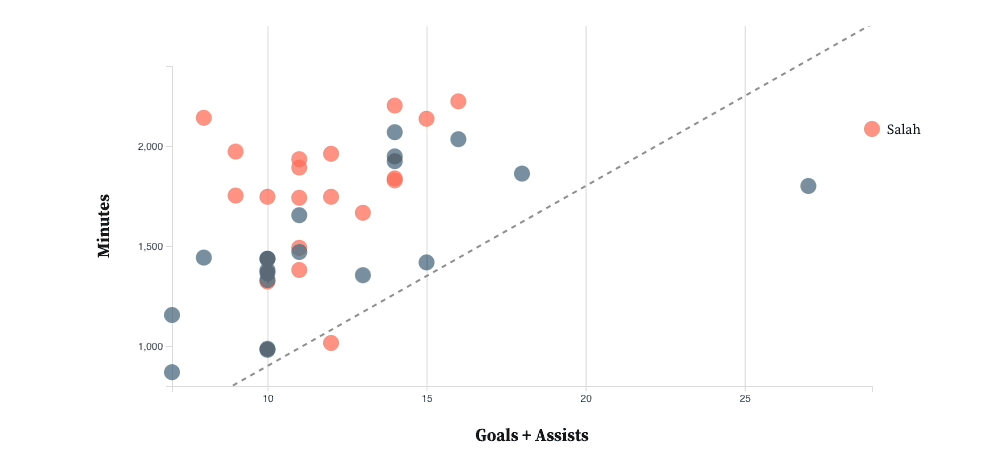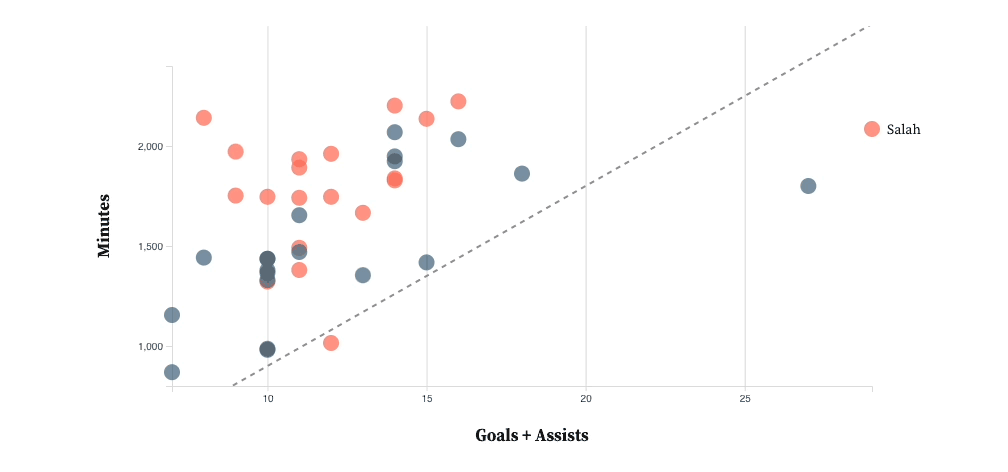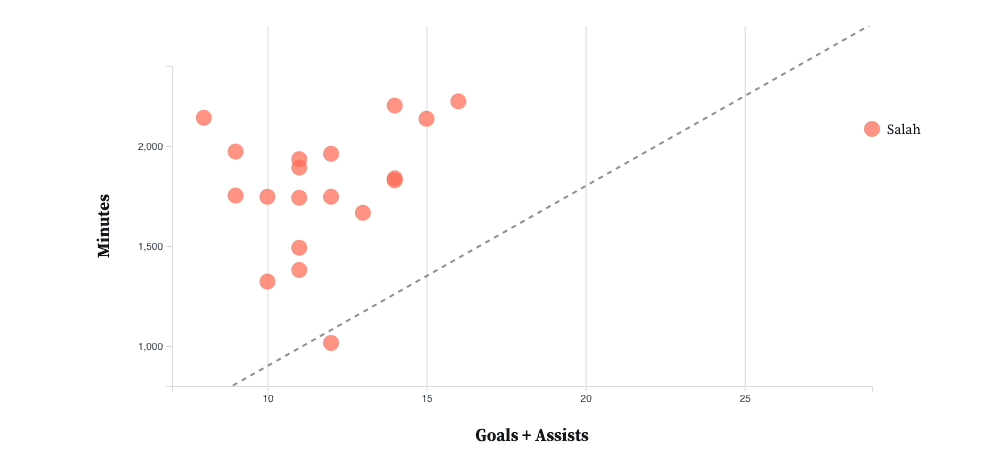
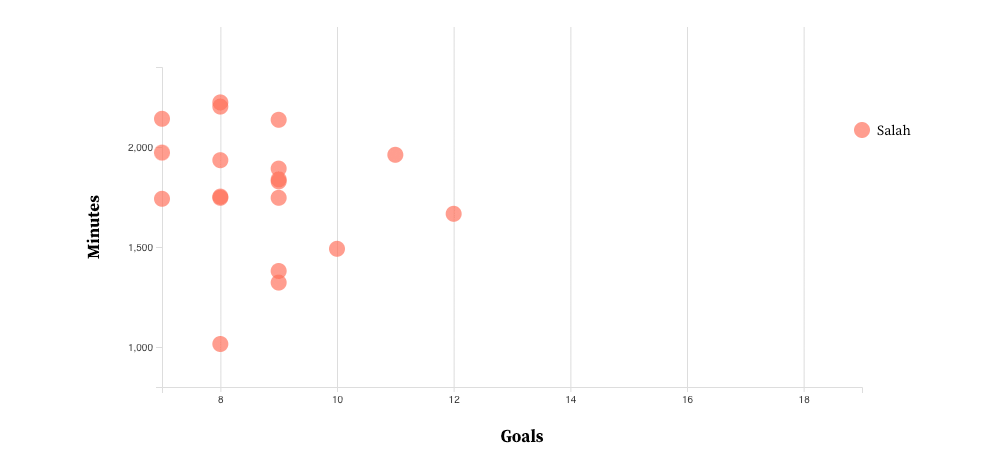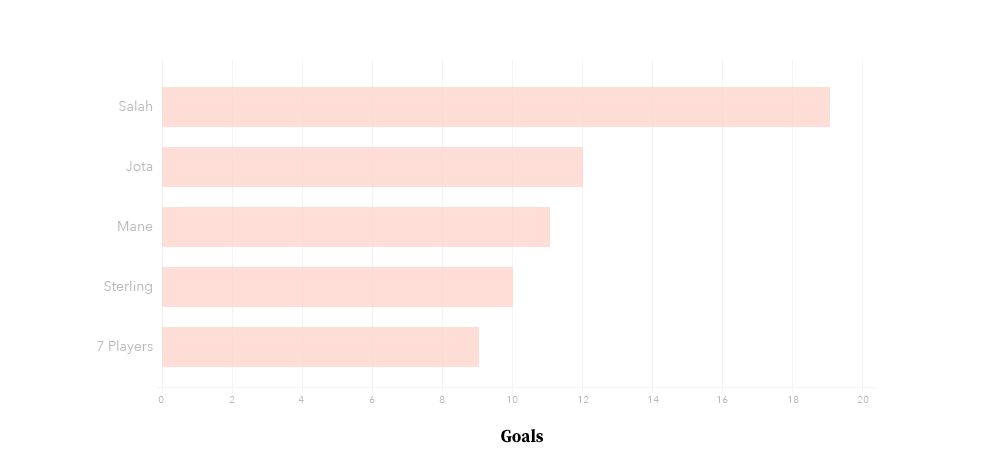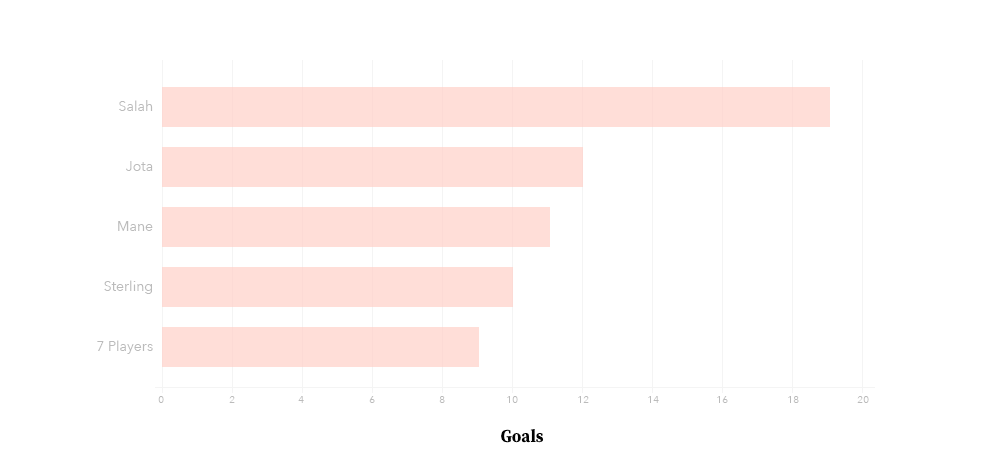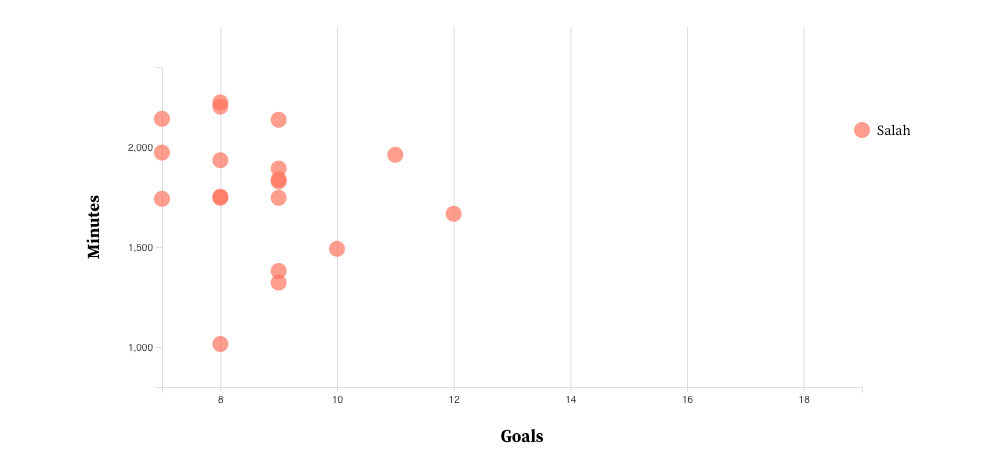
![Adding tooltips when a user hovers over a plot for more player information]](https://envylabs.com/wp-content/uploads/2022/03/interactive-6.gif)